Golang 指针
任何程序数据载入后,在内存中都有它们的地址,这个地址就是指针
- 寻址:对变量进行 &( 寻址 )操作,可以获取这个变量的内存地址
- 指针变量:为了保存这个变量的内存地址,需要定义一个指针变量
- 取值:对指针变量进行 * ( 取值 )操作,就可以获得原变量的值
- 内存分配:make() / new(),二者都是用来做内存分配的,区别在于
- make,只用于 slice、map 以及 channel 的( 引用类型 )初始化,返回的是这三个引用类型本身
new,用于类型的内存分配,返回的是指向类型的指针,且内存对应的值为类型零值Golang 中,指针不像 C 语言里,那么难理解,使用指针,可以更简单的执行一些任务
指针的声明与使用
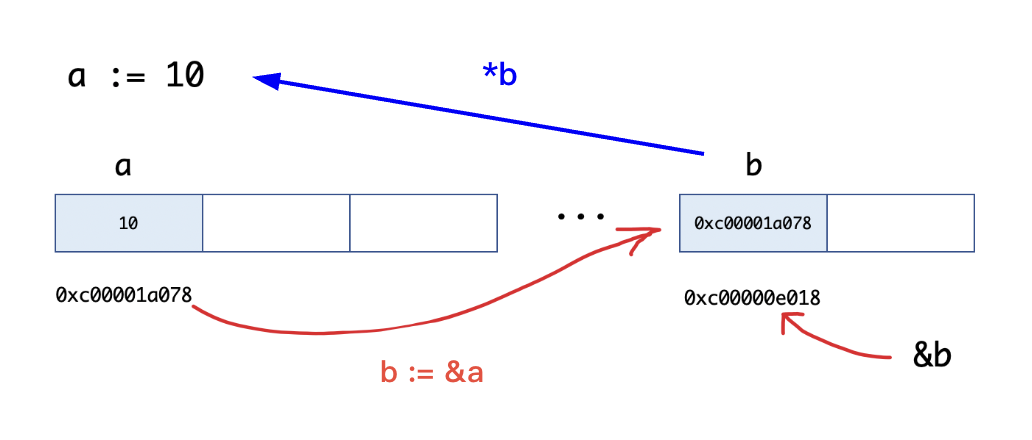
( 常规操作 ):声明指针变量( *type ) — 为指针变量寻址( & ) — 获取指针变量对应的内存地址的值( * )
(1)声明指针变量
Go 语言中的值类型( int、float、bool、string、array、struct )都有对应的指针类型,如:*int、*int64、*string 等
// (1)声明:var varName *varType var pointer1 *int // 指向int类型的指针变量 var pointer2 *float64 // 指向float64类型的指针变量 fmt.Println(pointer1, pointer2) // <nil> <nil> // 空指针判断:当一个指针被定义后,没有分配任何变量时,它的值为 nil,即:空指针 fmt.Println(pointer1 != nil) // false fmt.Println(pointer2 == nil) // true(2)为指针变量寻址( & )和获取指针变量对应的内存地址的值( * )
// (1)指针的寻址( & )和 取值( * ) var a int = 10 var aPointer *int = &a // 通过 & 寻址,内存地址 0x1400011c020 fmt.Println(aPointer) fmt.Println(*aPointer) // 通过 * 指向,获取具体的值 10 // (2)数组指针:首先,它是一个指针,然后,它指向数组 // 区别于(3)指针数组( 一个数组元素为指针的数组,具体见数组 ) arr := [5]int{1, 2, 3, 4, 5} var arrPointer *[5]int = &arr fmt.Println(arrPointer) // &[1 2 3 4 5] fmt.Println(*arrPointer) // [1 2 3 4 5] // (4)相应的,指针可以指向各种数据类型的内存地址 slice、map ... // (5)指向指针的指针( 可以有多级,以此类推 ) var b int = 10 // 具体的值 // 一级指针 var bPointer *int = &b fmt.Println(bPointer, *bPointer) // 0x140000a4050 10 // 二级指针:var ptr **int 使用 **ptr,可以获取具体的值 var bbPointer **int = &bPointer fmt.Println(bbPointer, *bbPointer, **bbPointer) // 0x14000120020 0x14000126050 10
( 内存分配 ):使用 new 函数( 分配内存 ),直接初始化不同类型的指针
// 对于值类型的声明,不需要分配内存空间,是因为,它们在声明的时候已经默认分配好了内存空间 var a int a = 100 fmt.Println(a) // 100 // 对于引用类型的变量,在使用的时候不仅要声明它,还要为它分配内存空间,否则,值就没办法存储 var b map[string]int //b["hello"] = 100 //fmt.Println(b) // panic: assignment to entry in nil map // Golong 中,new 和 make 是内建的两个函数,主要用来分配内存 b = make(map[string]int, 10) b["hello"] = 100 // map[hello:100] fmt.Println(b)「 new 」new 函数,是一个内置函数,实际中,并不常用
func new(Type) *Type // Type,表示类型,new 函数只接受这一个参数 // *Type,表示指针类型,new 函数返回一个指向该类型内存地址的指针var a *int // 指针,作为一个引用类型,必须分配内存后,才能赋值 // a = 100 // '100' (type untyped int) cannot be represented by the type *int a = new(int) // new 函数不太常用,使用 new 函数得到的是一个类型的指针,且,该指针对应的值为该类型的零值 fmt.Println(a) // 0x14000126008 fmt.Println(*a) // 0 // 使用 new 函数分配内存后,就可以正常赋值了 *a = 100 fmt.Println(*a) // 100「 make 」make 函数,也是用于内存分配的,区别于 new,它只用于 slice、map 及 channel 这三个引用类型的内存创建,因为这三种类型本身就是引用类型,所以,就没必要返回指针类型了,而是返回这三个类型本身
func make(t Type, size ...IntegerType) Type var b map[string]int b = make(map[string]int, 10) b["hello"] = 100 // map[hello:100] fmt.Println(b)
使用指针作为函数参数( 推荐 )
Golang 中的传值方式,是值传递,这意味着给变量赋值、给函数传参时,都是直接拷贝一个副本,将副本赋值给对方
这样的拷贝方式,意味着:
- 如果数据结构体积庞大,则要完整拷贝一个数据结构副本( 如,长度为 100w 的数组 )时,效率会很低
- 如果传递给函数的是:数组的指针,只需要 8 个字节就可以了 // 数组,是复合类型,不是引用类型
- 函数内部修改数据结构时,只能在函数内部生效,函数一退出就失效了,因为,它修改的是副本对象
实际上,对于引用类型来说,所谓的副本,是“引用”,所以,修改函数参数,对原数据也会产生影响func main() { // 使用指针作为函数参数 c := 100 d := 200 fmt.Println(c, d) // 100 200 swap(&c, &d) fmt.Println(c, d) // 200 100 } // 交换函数 func swap(x *int, y *int) { // 使用指针传值,将会对原数据进行修改 *x, *y = *y, *x }